
India has built one of the richest real-time data ecosystems in the world. Every day, millions of signals flow across payments, production, prices, and logistics. UPI processes billions of transactions. Factories file GST returns. Trucks pass through FASTag toll plazas. Satellites map infrastructure buildouts across sixteen ministries. Quick commerce platforms record SKU-level pricing every hour. The signals are abundant — yet most arrive as unstructured PDFs, HTML tables scraped from government portals, or Excel files locked behind CAPTCHAs, login walls, and rate-limited download queues.
This gap between data abundance and data usability will define whether India can lead in AI or merely consume it. The country generates more diverse, more frequent, and more granular economic data than most advanced economies. Yet almost none of it is AI-ready — and no amount of compute or model sophistication can compensate for data that is messy, unstandardised, and inaccessible.
What does AI-ready mean? It means standardised APIs instead of custom scrapers that break overnight when a portal redesigns its HTML; documented schemas instead of portals where every ministry invents its own format; full revision history instead of GDP, IIP, and trade figures that are silently overwritten months after release with no concordance tables; and machine-readable metadata — data dictionaries, frequency indicators, methodology notes — so that models can ingest information without weeks of human preprocessing. Today, approximately 80% of analyst time in India goes into cleaning data, not analysing it, and no Indian alternate data source ships with API documentation or a schema.
The government has started — and the early moves are significant
On 6 February 2026, the Ministry of Statistics and Programme Implementation launched a Model Context Protocol server on its eSankhyiki portal — the first time a government statistical agency anywhere has allowed AI tools to query official data directly, without file downloads or preprocessing. Seven datasets went live at launch: consumer prices, industrial production, labour force surveys, wholesale prices, national accounts, annual industry surveys, and energy statistics.
Three initiatives that can change the picture
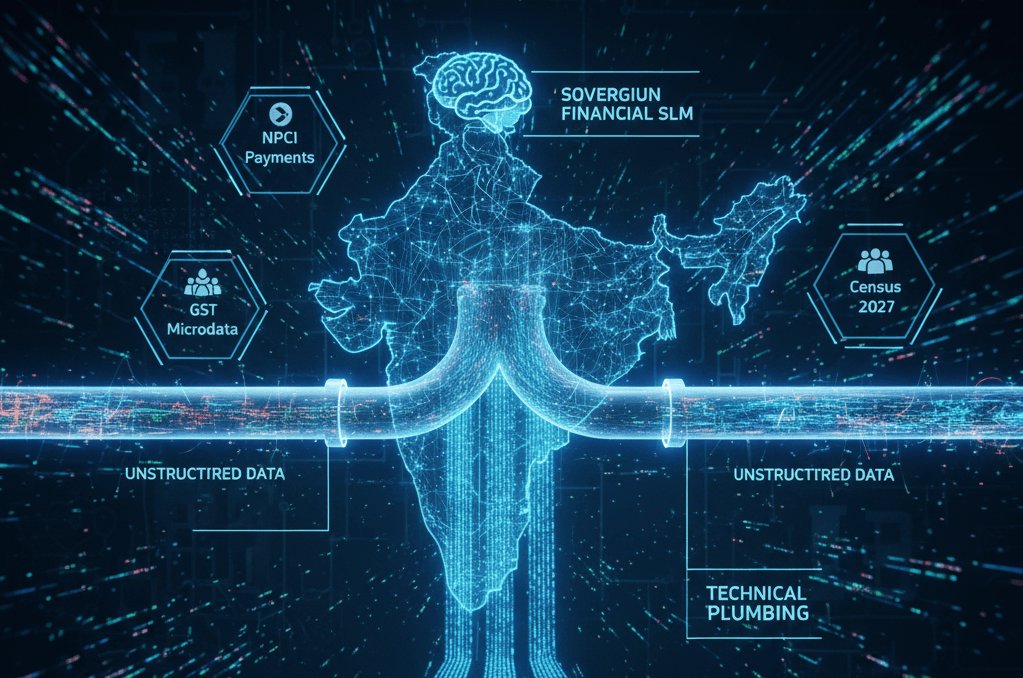
The first initiative is to open up six transformative datasets: (a) GST revenue microdata — collection by sector and state — which would let researchers map economic density and identify growing industrial clusters in near real-time; (b) NPCI payment trends at merchant and sectoral level, providing consumer spending signals that today simply do not exist in any accessible form; (c) MCA company financials — annual filings, director changes, charge filings, and incorporation data across all registered entities — enabling sectoral health assessment, credit risk modelling, and corporate governance analytics; (d) MoSPI’s survey microdata at the unit level from the Periodic Labour Force Survey, consumer expenditure rounds, and health surveys; (e) PM Gatishakti’s spatial datasets covering rail, road, port, and logistics infrastructure; and (f) administrative records from hospitals, EPFO, power distribution companies, and vehicle registrations. Together, these six would provide the foundation for an entirely different quality of economic analysis.
The second initiative is to build a sovereign small language model for Indian finance and economy. General-purpose LLMs do not understand Indian regulatory filings, company naming conventions, or the idiosyncrasies of how Indian data is structured. Indian CPI ses a different basket and methodology from the US; IIP classification codes, GST filing formats, and MCA annual return schemas do not exist in any global training corpus; and SEBI circulars, RBI master directions, IRDAI guidelines, and TRAI regulations — thousands of pages of domain-specific rules — shape how Indian markets, banks, and insurers operate. Promoter pledging patterns, related-party transactions, Indian GAAP to Ind-AS transitions, and group structures with dozens of subsidiaries are patterns that only emerge from deep exposure to Indian filings. A domain-specific SLM, trained on this data and hosted on Indian infrastructure, can outperform generic models at a fraction of the cost while keeping sensitive financial intelligence within India’s borders.
The window is now
Other countries are already moving: the UK’s Office for National Statistics is building API-first data pipelines, and Singapore’s government data portal already serves machine-readable datasets by default. India has a richer data ecosystem than either. What it lacks is the plumbing. The three initiatives outlined here — opening datasets, building a sovereign SLM, and designing Census 2027 for AI from the start — are concrete, achievable, and would place India at the frontier of AI-ready national data infrastructure. The data exists. Now make it usable.
Cover photo credit: AI-generated
View disclaimer
For a structured summary of the key arguments and the three proposed initiatives, download the full deck: Making India’s Data AI-ready
Unlock the power of alternative data
Do not just follow the market — stay ahead of it. Thurro helps you transform raw filings and alternative datasets into actionable insights.
Explore Thurro AltData Book a demoRelated Articles

Human AI collaboration using Thurro Answers
How does the language of the Union Budget evolve as […]

Five learnings from building AI for finance in India
What building institutional AI has taught us about data, discipline, and the future of financial workflows in India

AI in India Inc: from hype to measurable impact
The era of vague AI strategy is over. Q1 FY26 earnings reveal a critical shift: India Inc is…